fb-hitler Updated
I updated fb-hitler a few years ago and never wrote about it; today I spent some time to describe the new version, which is implemented more robustly: now it’s a bootable image that runs in real mode, not a Linux application.
I updated fb-hitler a few years ago and never wrote about it; today I spent some time to describe the new version, which is implemented more robustly: now it’s a bootable image that runs in real mode, not a Linux application.
FPGAs are pretty cool pieces of hardware for tinkering with, and have become remarkably easy to approach as a hobbyist in recent years. Boards like the TinyFPGA BX don’t require any special hardware to use and can provide a simple platform for modestly-scoped projects or just for learning.
While historically the software tools for programming FPGAs are proprietary and provided by the hardware manufacturer, Symbiflow (enabled and probably inspired by earlier work like Project IceStorm) provides completely free and open-source tooling and documentation for programming some FPGAs, significantly lowering the cost of entry (most vendors provide some free version of their design software but limited to lower-end devices; a license for the non-free version of the software is well into the realm of “if you have to ask, you can’t afford it”) and appearing to yield better results in many cases.1
As somebody who finds it fun to learn new things and experiment with new kinds of creations, FPGAs are quite interesting to me- they’re quite complex devices that enable very powerful creations, with excellent depth for mastery. While I did some course lab work with Altera FPGAs in university (and a little bit of chip design/layout later), I’d call those mostly canned tasks with easily-understood requirements and problem-solving approaches; it was sufficient to familiarize myself with the systems, but not enough to be particularly useful.
The announcement of Fomu caught my interest because I was aware of the earlier Tomu but wasn’t sufficiently interested to try to acquire any hardware. With Fomu however, I’m rather more interested because it enables interesting capabilities for playing with hardware- others have already demonstrated small RISC-V CPUs running in that FPGA (despite its modest logic capacity), for instance.
Even more conveniently for being able to play with Fomu, I’ve been in contact with Mithro who is approximately half of the team behind Fomu and gotten access to a stockpile of “hacker edition” boards that have been hand-assembled but not programmed at all. With slightly early access to hardware, I’ve been able to do some exploration and re-familiarize myself with the world of digital logic design and figure out the hardware.
Previously as I was experimenting with logging the temperature using a Raspberry Pi (to monitor the temperatures experienced by fermenting cider), I noted that the Pi was something of a terrible hack, and it should be possible to do more efficiently with some slightly less common hardware.
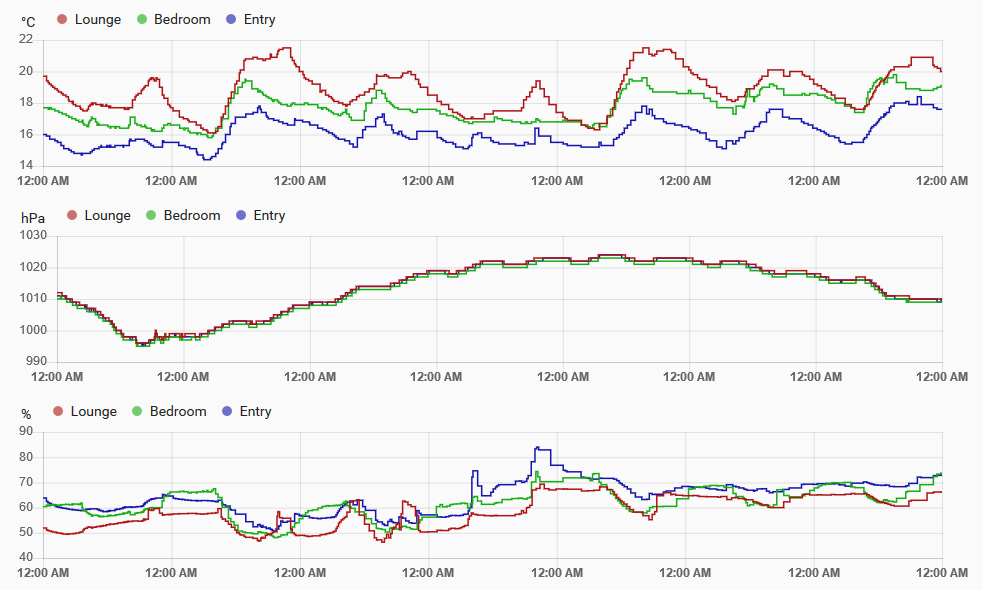
I decided that improved version would be interesting to build for use at home, since it’s both kind of fun to collect data like that, and actually knowing the temperature in the house is useful at times. The end result of this project is that I can generate graphs like the one below of conditions around the house:
I had approximately the following exchange with a co-worker a few days ago:
Them: “Hey, do you have a spare Raspberry Pi lying around?”
Me: [thinks] “..yes, actually.”
T: “Do you want to build a temperature logger with Prometheus and a DS18B20+?
M: “Uh, okay?”
It later turned out that that co-worker had been enlisted by yet another individual to provide a temperature logger for their project of brewing cider, to monitor the temperature during fermentation. Since I had all the hardware at hand (to wit, a Raspberry Pi 2 that I wasn’t using for anything and temperature sensors provided by the above co-worker), I threw something together. It also turned out that the deadline was quite short (brewing began just two days after this initial exchange), but I made it work in time.